Web Domains (Part 2: Context, Definition, and Uniform Resource Locators)
We've talked about the high level of internet addresses. Now we're going to dive into what's behind those website names (Known as Uniform Resource Locators; abbreviated to URLs) that you find yourself typing into your browser to access popular websites like Google, YouTube, and Facebook. They are the human readable form of network format + network addresses + resource requests that allow your personal computers (mobile devices, laptops, desktops) to access and interact with server networks hosted by various entities. Think of your personal devices as being your digital home, and server networks in the digital world behave like various department stores, shops, and services in relation to your digital home.
Providing some more context that wasn't covered in the last article. The internet is just a bunch of computers, and any group of computers connected together is called a network. Similar to how humans refer to networking as connecting with each other, we use the same term in computing for a group of computers connected together. The internet is just the term we give to the main network that connects all sub networks together. In any network there has to be a way for the computing machines to pass messages back and forth. This is the basis for a study of computing called networking. In the basics of networking you'll learn how there are dedicated machines setup for message passing call network devices. They behave like post office robots for computers, and they have a formal way of assigning addresses to the machines that are connecting to them.
The addresses that network devices assign are IPv4 or IPv6 addresses, and they are easy to read and understand by machines, but like phone numbers are difficult to remember by humans. Examples of them look like this: (IPv4 -> 12.244.233.165), (IPv6 -> 2001:0db8:0000:0000:0000:ff00:0042:7879). These addresses are assigned to every computer that connects to any computing network, and each device gets one of each. The reason you get one of each is because IPv4 wasn't designed with a large enough address space for how many computers we have today. Our growth scale has surpassed it, and IPv6 was created to handle a larger address space. However, even though IPv6 has been around for many years, it hasn't been commonly adopted and the network needs to support both so that older setups can still function properly. So when you connect to your WiFi at home, your device is getting one of each of these addresses, and they are what allow your device to access the internet and receive the responses from your web requests.
Fun factoid is that IPv4 can handle 4,294,967,296 addresses; close to 4.3 billion. IPv6 on the other hand can handle 340,282,366,920,938,463,463,374,607,431,768,211,456 addresses. It's honestly incredible to see that fully written out and to see how large it is. The idea is that the address space in IPv6 is so large that every device ever made could have its own unique address. In IPv4, we've already created so many devices that there isn't enough room for each device to get its own. To deal with this, we've created sub networks that have one or a few dedicated IPv4 addresses that can be accessed from outside it via the public internet. Inside of those sub networks they have another separate address space that acts as its own internet and it allows reuse of IPv4 address ranges internally. Think of how multiple cities can have the same road name, but that we don't confuse them because they aren't located in the same geographical area. That's the same concept used for networking to allow the server networks to run properly without colliding with the public internet's list of addresses.
How does this get over to what a web domain is? Well, the web domain is what organizes the sub networks that exist around the world into easily read and remembered text names. It's also a critical part of networking that allows underlying IP addresses to be linked to a name that doesn't change even though the IP addresses can change. It's hierarchical, like a tree structure, and all starts with what we call top level domains (TLD). The root level is the highest above all the top level domains, and it is the dot (.). However, that dot is largely implicit, so you don't see it explicitly typed out in web addresses. All web domains are implicitly connected to dot, so that there is a common root for all of the TLD to branch from.
Web domains are read right->left instead of left->right like the English language, and they are organized by a group called the Internet Corporation for Assigned Names and Numbers (ICANN) that owns all of the top level domains that exist in the internet. Top level domains (TLD) are the right most part of a web domain address with common examples being '.com', '.org', '.net', and '.info'. ICANN is responsible for all of these names, but they do delegate the management of the naming servers of the TLDs to certain companies as well. For instance, a U.S. company called Verisign manages the TLDs of '.com' and '.net'.1 There are many TLDs, and each of them is for a specific purpose. There are ones for generic use like '.com', ones that are specific to a country like '.uk' for the United Kingdom, ones that are sponsored like '.app' by Google, there's one for infrastuctural purposes like the first ever created TLD '.arpa', and reserved TLDs like '.localhost' which is used for local application development.1
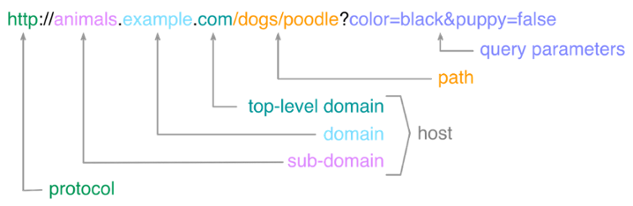
Now how do URLs relate to this? Well they are the string of characters that designate client requests to servers looking for information. [In computer programming, text is commonly referred to as a string. Dubbed so because a string of individual characters make up words, sentences, labels, or other structures that we can use to identify certain aspects of computing with.] The Uniformed Resource Locator (URL) is a structured string that breaks down an internet/web request into specific parts that the individual computers on the internet use to pass messages. The image at the top of this article displays most of them, but we'll break them down here below.
Using the example above we have: http://animals.example.com/dogs/poodle?color=black&puppy=false
- Protocol: http
- Protocol and domain separator: ://
- Sub-Domain: animals.
- Domain: example.
- Top Level Domain: com.
- Path: /dogs/poodle
- Query Parameters Separator: ?
- Query Parameters (the ampersand is the separating character): color=black&puppy=false
The URL parts above specify different aspects of a network request created by a client being sent to a server. The protocol specifies the network rules that are used to transmit the data between the two entities, and in this case it is the Hyper Text Transfer Protocol (HTTP). The domain portions are used to determine the address of the server by using Domain Naming System (DNS) to map the chain of names to an IP address on the internet (IPv4 or IPv6); in this case the domain is a sub-domain of example.com and is animals.example.com. The path identifies the specific resource on the server that the client is trying to access; which is /dogs/poodle, so we're trying to find a dog that is of the poodle variety. Finally, the query parameters are additional key-value pairs of data that are sent to further filter the resource that is being requested at the given path; which are color=black&puppy=false, so in this case we're looking for a black poodle that isn't a puppy.
Putting that all together, and you have a fully defined URL that is attempting to request a resource (a file, some data, pictures, or all of the above) from a server. However, just because the request is well defined, doesn't mean that there is anything on the other end to receive it. That's why sometimes when you type a URL into your browser window it will tell you that it can't find it or that it doesn't exist. This could be because server doesn't even have that resource, or may not be configured to handle requests looking for /dog/poodle. It could even be that a server hasn't been linked to the domain of animals.example.com. So there's an important distinction to be made that even though a client may request something, there has to be a computer programmed to receive the request otherwise the request will fail. There are a plethora of reasons why a request could fail as well, and with regards to HTTP requests the error codes returned help the client identify and remediate the issues. We're going to table this thought though and return to it later on when we discuss some of the common computing layers present today. They are what allow us to break up website productions into separate portions so that we can build more robust products more efficiently.
An additional omitted part of the URL is the port, which appears between the domain labels and the path. The reason that it can be omitted here is that the protocol chosen, HTTP, has default connection ports of 80, and 443. The chosen port depends on whether or not the server is serving the content with clear text on port 80 or with Transport Layer Security (TLS; previous version was named Secure Socket Layer - SSL, and SSL is still a common term in computer tooling) on port 443. If not specified the request will default to 80, but the server can use port redirection on its end to force the client request to change to port 443. It can do this programmatically in the application layer, or it can handle it with a production web server. The concepts of application layer and production layer will get discussed later on as well when we dive into website building.
Explicitly stating the port would change the URL to something similar to, http://animals.example.com:80/dogs/poodle?color=black&puppy=false, with the port being any number up to 65,535 (without the comma). However, not all ports are available for independent use and some are reserved for specific software companies or common software products.2 So the important distinction is that after the domain name, and before the path, we can explicitly state the port with :<port_number>.
Alright, we're definitely getting into it now. That's enough for Part 2. We're going to pick it up again in Part 3. To summarize what's been covered to this point; a high level introduction to internet concepts, context to why web domains exist, a brief web domain definition and introduction, and introduced how web domains are commonly used by describing some portions of Uniform Resource Locators. The pace is starting to pick up, so it may be best to couple your readings of these articles with your own research. If I've made any errors here, or you have feedback you'd like to share, please leave a comment and I'll get to it as soon as I'm able.
Part 3 will start to get into Web Development concepts through discussion of common web application breakdowns. Then we'll tie that into how the web domain connects to a web application to allow it to serve traffic on the human readable name. Things that we're starting to get into will be DNS Management Companies, Cloud Providers, and web application layers (front end/back end). Networking will be an aspect of how everything connects together so as we go forward it's going to be an ever present theme.
We're starting to get to the most interesting and fun bits. Going to get more complex as well so comment your questions if you have any. Thanks for reading, and I hope you enjoyed it! :)
Cheers,
DaSeventhHogie
Bibliography: